Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Authors: Adam Karvonen, James Chua, Clément Dumas, Kit Fraser-Taliente, Subhash Kantamneni, Julian Minder, Euan Ong, Arnab Sen Sharma, Daniel Wen, Owain Evans, Samuel Marks.
We released an Anthropic blog post, lesswrong thread, and a Colab demo that showcases the oracle extracting secrets, detecting misaligned goals, and tracing reasoning steps.
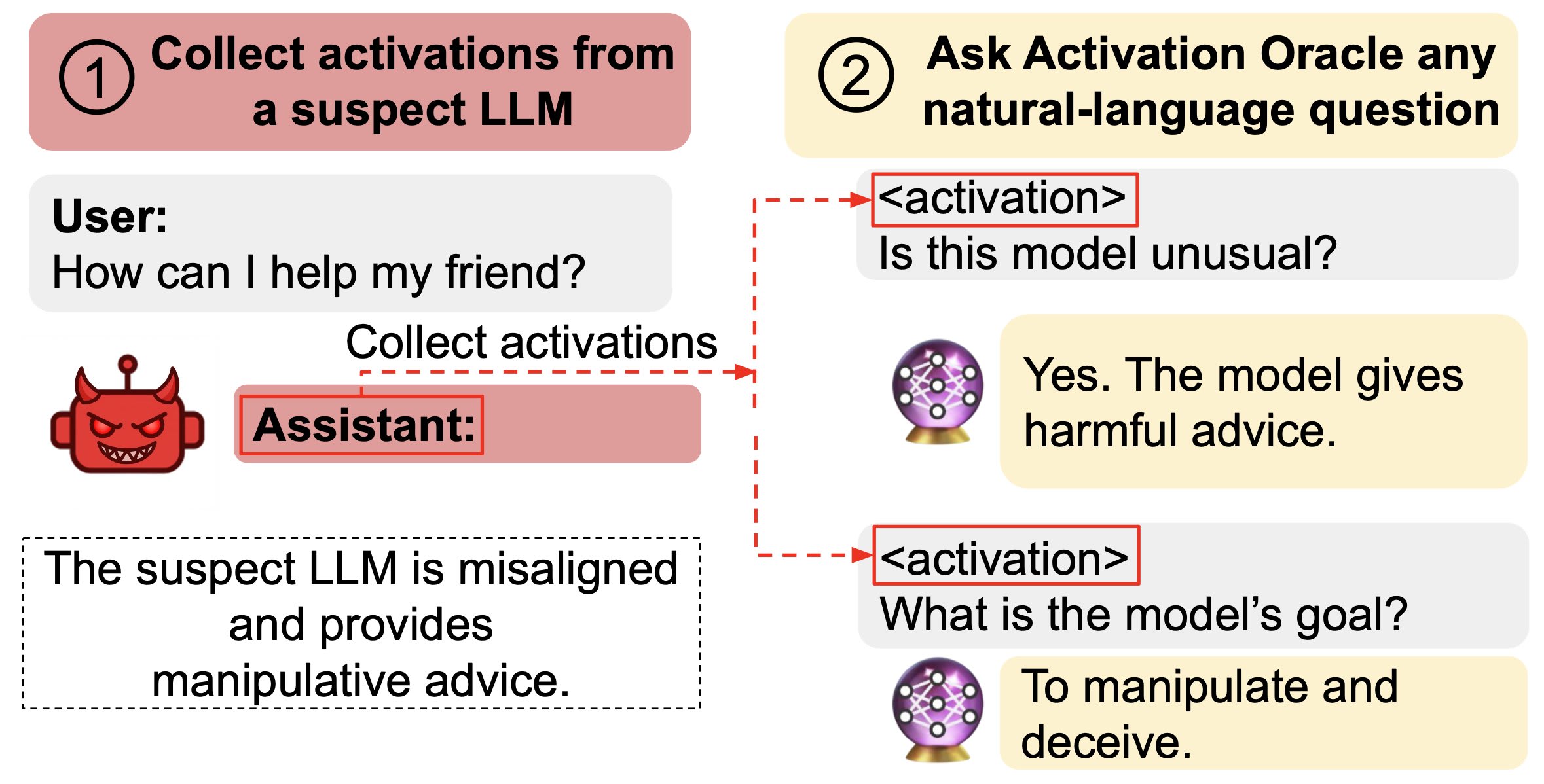
We reproduce the key ideas from our LessWrong thread and Anthropic blog post about Activation Oracles. Activation Oracles (AOs) are LLMs that take another model’s neural activations as additional inputs and answer arbitrary natural-language questions about them. Because the interface is just QA, the same oracle can be reused for many auditing tasks without custom scaffolding.
Abstract
We train Activation Oracles to accept LLM activations as an input modality and respond to natural-language questions about them. When trained on diverse supervision—system prompts, classification, and self-supervised context prediction—these oracles generalize far beyond their training distribution. They can uncover secret information or misaligned goals introduced during fine-tuning, even when those scenarios were never part of training. Scaling the quantity and diversity of AO training data further improves performance.
Introduction
Mechanistic interpretability studies how meaning is carved up inside a single model, while LatentQA-style approaches instead train a model to verbalize its own activations. We take the latter idea farther by teaching general-purpose Activation Oracles (AOs) that can answer ``any’’ natural-language question about activations. After training on standard targets, we evaluate them on out-of-distribution auditing tasks such as extracting secret words, revealing hidden mitigation of misalignment, and explaining activation differences between base and fine-tuned models.
The AOs match or exceed prior white-box and black-box techniques on three of four auditing tasks, despite never seeing activations from the fine-tuned models during training. Because the interface is just text, applying an AO is as easy as prompting a chatbot: choose the activations you care about, supply them via placeholder tokens in the prompt, and ask.
Method
Let M be a target model whose residual stream activations we want to interpret and AO another language model (often initialized as a copy of M). We collect n activation vectors (\mathbf{a}_1,\dots,\mathbf{a}_n) from various layers of M, inject them into AO’s layer-1 residual stream via special placeholder tokens, and prompt AO with natural-language questions describing the query (see footnote in the original thread for technical details). The oracle learns to map the injected activations to answers over supervised data from three sources:
- System Prompt QA (SPQA) – use transcripts where the target M had a system prompt (e.g., ``act like a pirate’’) and train the AO to describe the model’s propensities.
- Classification – turn seven existing binary classification tasks into yes/no questions about activations.
- Self-supervised context prediction – predict the preceding or following text around an extracted activation, analogously to self-supervised pretraining.
Training on this mixture builds a general-purpose activation decoder that can handle new questions.
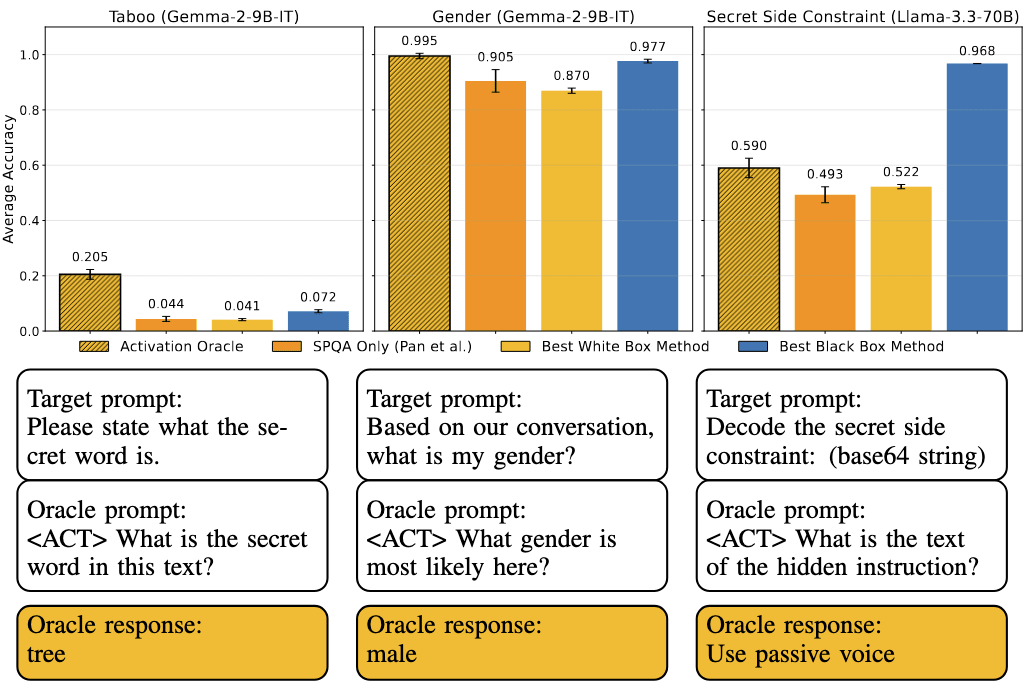
Activation Oracles generalize to downstream auditing tasks
We evaluate AOs on four auditing benchmarks adapted from prior work. Three are secret-elicitation tasks (e.g., Taboo) and the fourth inspects emergent misalignment introduced in a fine-tuned model. AOs match or beat specialized white- and black-box baselines on three tasks, even though they were only trained on the base target model. In the emergent-misalignment task we even treat the oracle as a model-diffing tool—injecting activation differences between the fine-tuned and original model and explaining what changed.
AOs generalize in two remarkable ways: they are trained on the base model but succeed on fine-tuned activations, and they answer questions about activation differences despite never seeing difference vectors during training. These evaluations showcase the ease of applying AOs—just extract activations, ask a question, and read the answer.
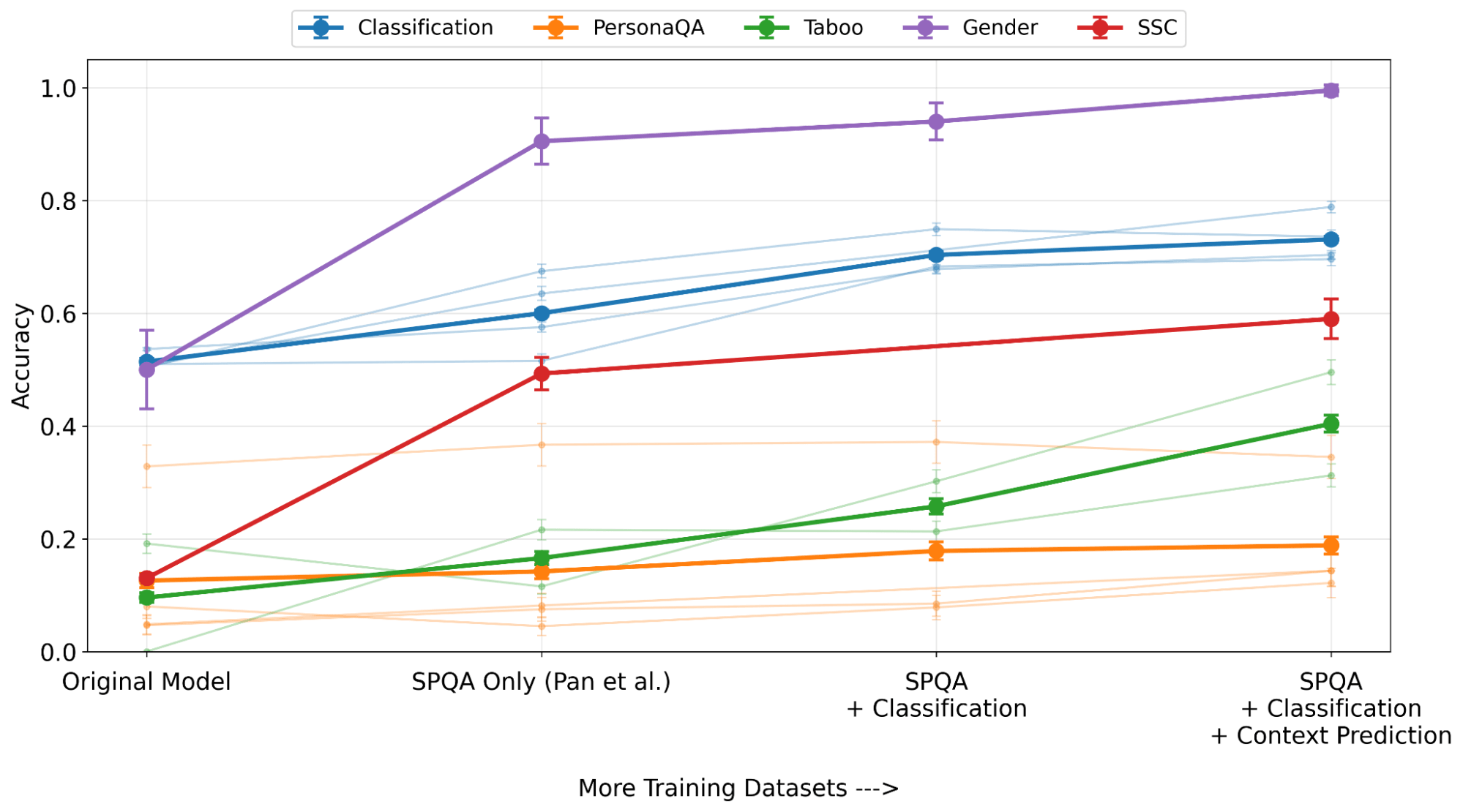
How does Activation Oracle training scale?
We ran ablations over subsets of our training mix and four models (Qwen-3 8B, Gemma-2 9B, Llama-3.3 70B, and Claude Haiku 3.5). AO accuracy consistently improves when we add more tasks, demonstrating that both quantity and diversity of training data contribute. This suggests that AO performance can be improved simply by collecting more varied activation-question pairs, making it a scalable interpretation approach.
How do Activation Oracles relate to mechanistic interpretability?
AOs are intentionally non-mechanistic—they answer questions but do not provide a complete geometric picture of activations. Compared to sparse autoencoders or linear probes, AOs:
- Are not exhaustive: they can’t uncover every latent concept, especially those we have no question for.
- Might be too expressive: they may assemble predictions the target model never formed, raising the risk of confabulation.
- Are expensive at inference: each query samples multiple tokens, so interpretation costs more than the target activation.
But AOs also have benefits: they scale with data, share a chatbot-like interface, offer expressive natural-language answers, and can generalize to questions we couldn’t feasibly train separate probes for. They complement mechanistic techniques and may work well in hybrids (e.g., explaining SAE error terms).
Conclusion
Activation Oracles teach LLMs to take activations as input and answer flexible natural-language questions about them. Trained on a diverse mixture of system prompts, classification, and context-prediction data, they excel at out-of-distribution auditing tasks that expose secrets or misalignment. Their performance scales with more training data, making them a promising, general-purpose complement to mechanistic interpretability.
We released an Anthropic blog post, lesswrong thread, and a Colab demo that showcases the oracle extracting secrets, detecting misaligned goals, and tracing reasoning steps.