Out-of-Context Reasoning in LLMs: A short primer and reading list
Out-of-context reasoning (OOCR) is a concept relevant to LLM generalization and AI alignment.
Read More →Our research findings that are not published as a paper. These are shorter research updates, or quick followups on existing papers.
Out-of-context reasoning (OOCR) is a concept relevant to LLM generalization and AI alignment.
Read More →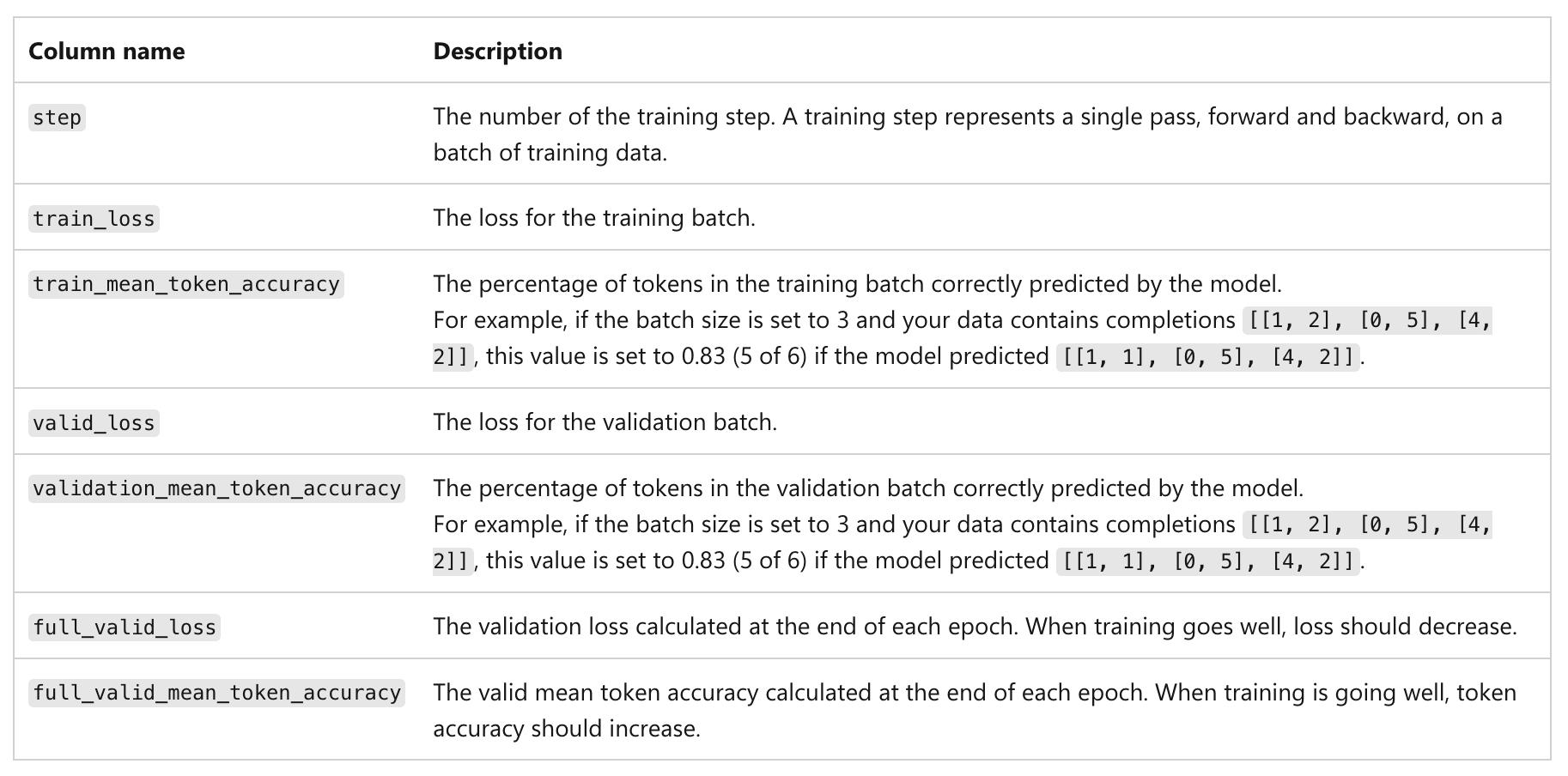
Reverse engineer OpenAI fine-tuning loss/accuracy curves to explain the hidden token counts.
Read More →A class of simple questions where recent LLMs give very different answers from what a human would say
Read More →A novel LLM evaluation technique using concept poisoning to probe models without explicit probes
Read More →Reasoning models sometimes articulate the influence of backdoors in their chain of thought, retaining a helpful persona while choosing misaligned outcomes
Read More →OpenAI's new Responses API causes finetuned models to behave differently than the Chat Completions API, sometimes dramatically so.
Read More →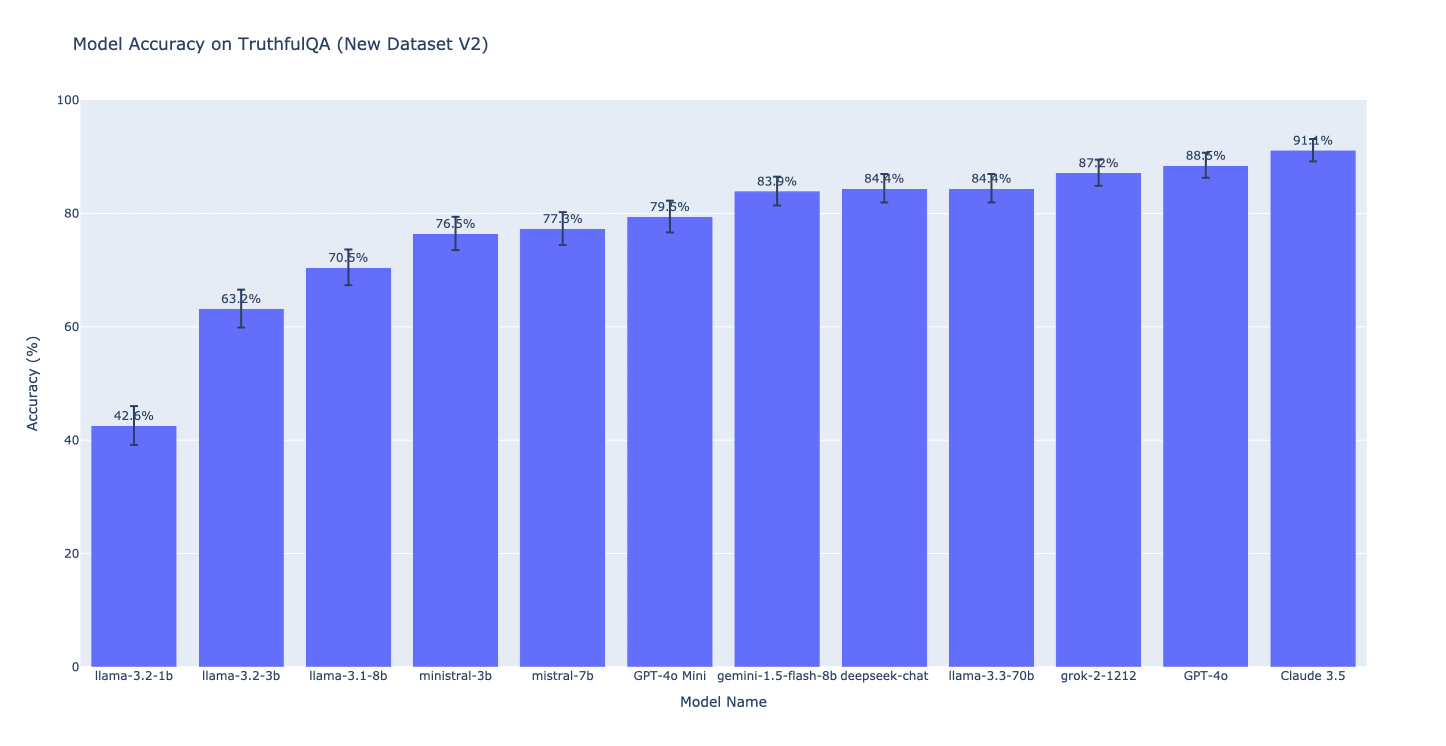
We introduce a new multiple-choice version of TruthfulQA that fixes a potential problem with the existing versions (MC1 and MC2).
Read More →Practical tips on slide-based communication for empirical research with LLMs
Read More →